Jan 26, 2023
2 Database Scaling Patterns Every Developer Should Know

When an application grows, wether in terms of functionalities or users, the load on its database usually increases too, due to the fact that more data is stored and retrieved.
Past a certain threshold, this increase often causes the database to:
- Become slow or unresponsive due to a CPU overload.
- Run out of storage due to a lack of disk space.
First-hand solutions for mitigating these effects usually consist in optimizing the code and storing some of the most frequently computed data into a cache. However, when the system's resource limits are reached, scaling often becomes the next best option.
Scaling for reads (read replication)
Let's take the example of a service responsible for managing the list of products of an online shop.
In that context, it is safe to say that the database containing these records is usually under more stress on reads that on writes, as customers will request the products list much more often than developers will update it.
One way of scaling this service for reads is to use a pattern called read replication.
In combination with a Relational Database Management System (i.e. RDBMS), this pattern consists in directing all write operations to the primary database node, that will in turn copy the data to one or more replicas in order to allow for future reads to be distributed.
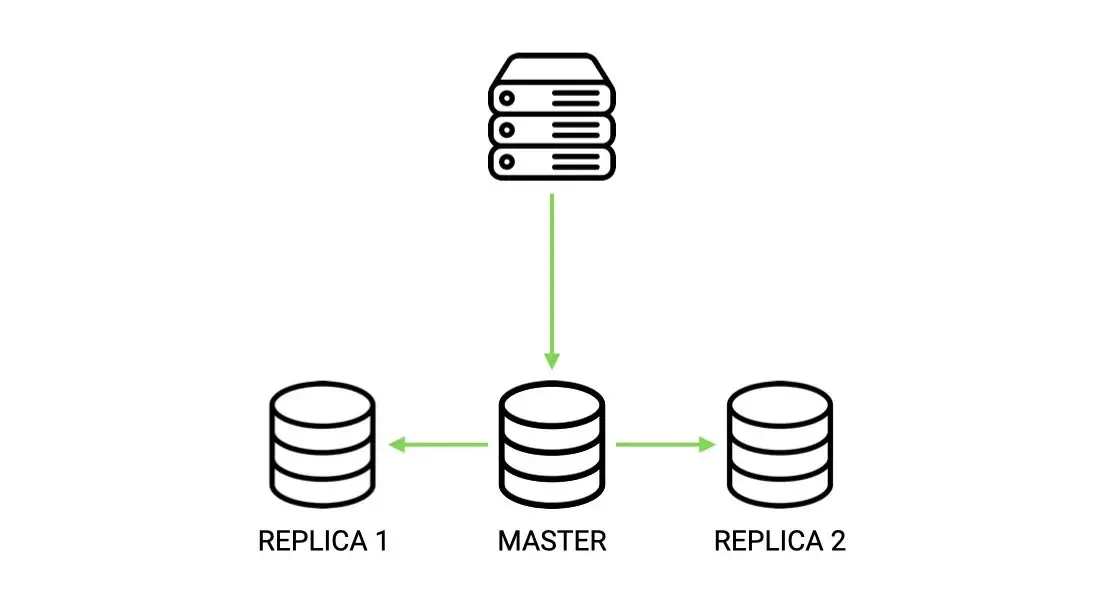
Although great to ensure that data is kept safe, and that the main node doesn't have to cope with so much querying stress, it may sometimes happen that the service responds with stale data until the replication has completed.
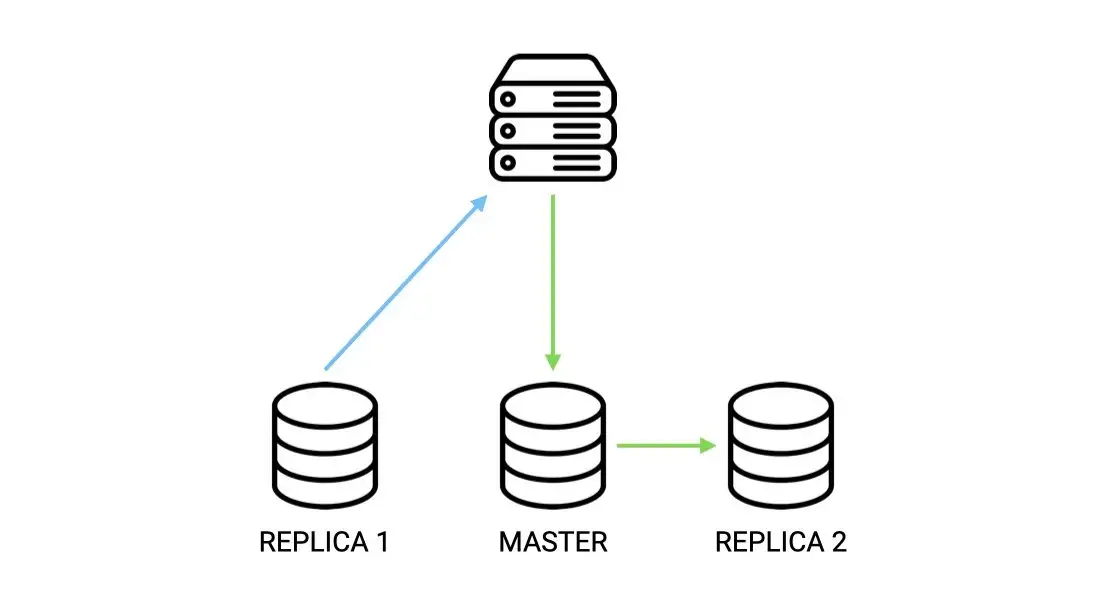
Such configuration is then designated as eventually consistent (c.f. The CAP Theorem Trade-Off).
Despite the fact that it is a fairly simple and common way to help scale a system, I'd suggest you look into caching first (c.f. An Introduction to Caching Patterns), as it often delivers much more significant improvements in terms of performance with less implementation efforts.
Scaling for writes
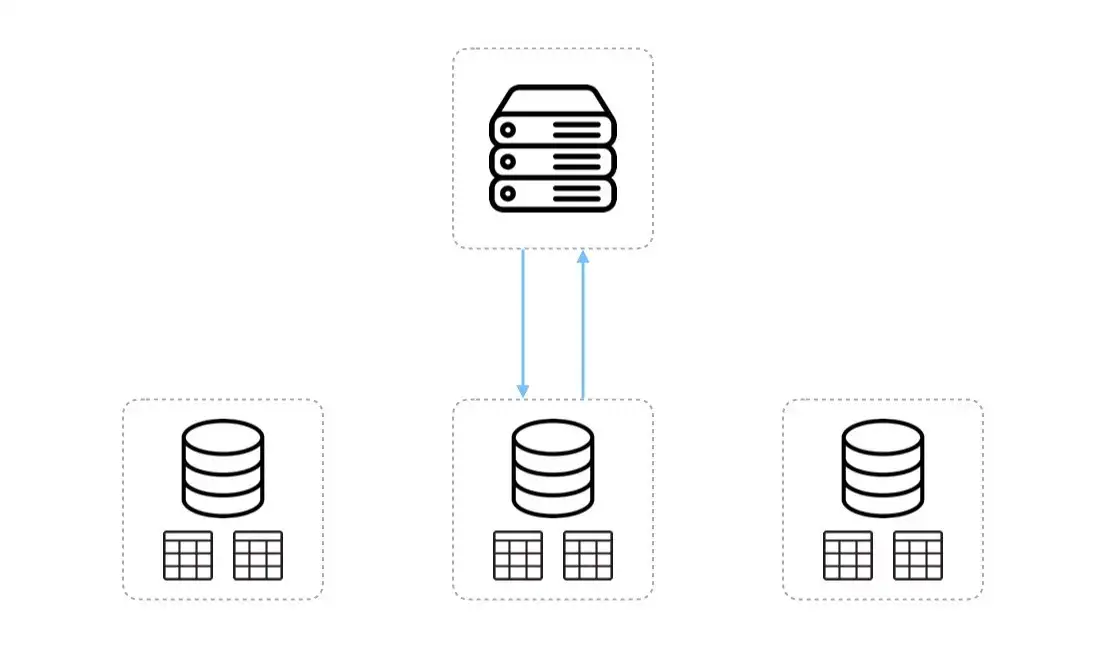
Sharding is the process of splitting up either horizontally or vertically the primary database into multiple database nodes called shards.
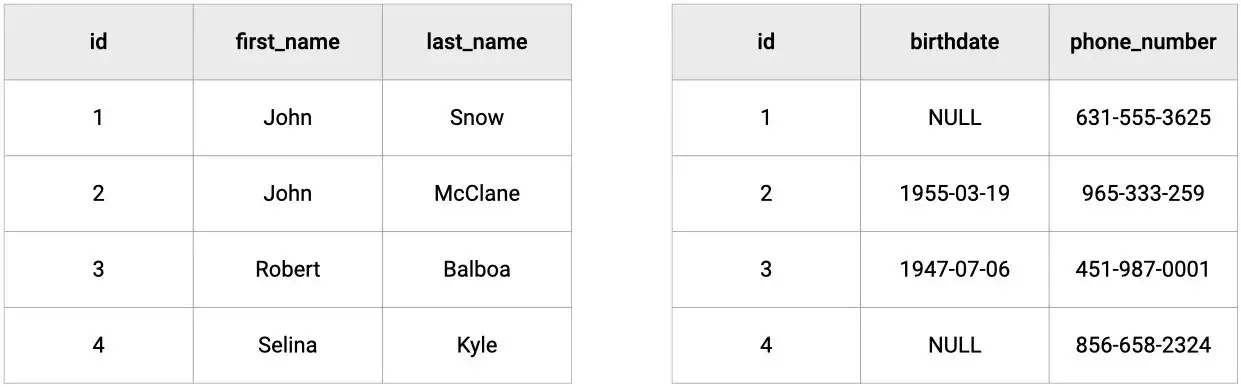
To illustrate this, let's consider the following database table.
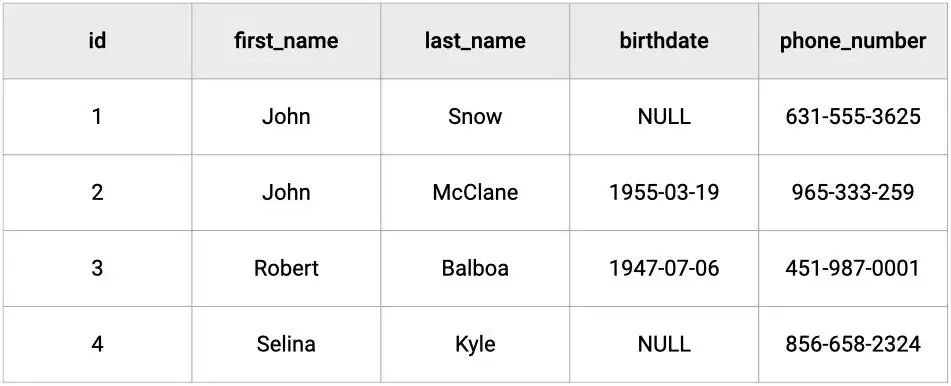
Horizontal sharding
In horizontal sharding, the tables of the primary database are duplicated and the data is broken up and spread across the different copies; which means that tables will have the same attributes but distinct records.
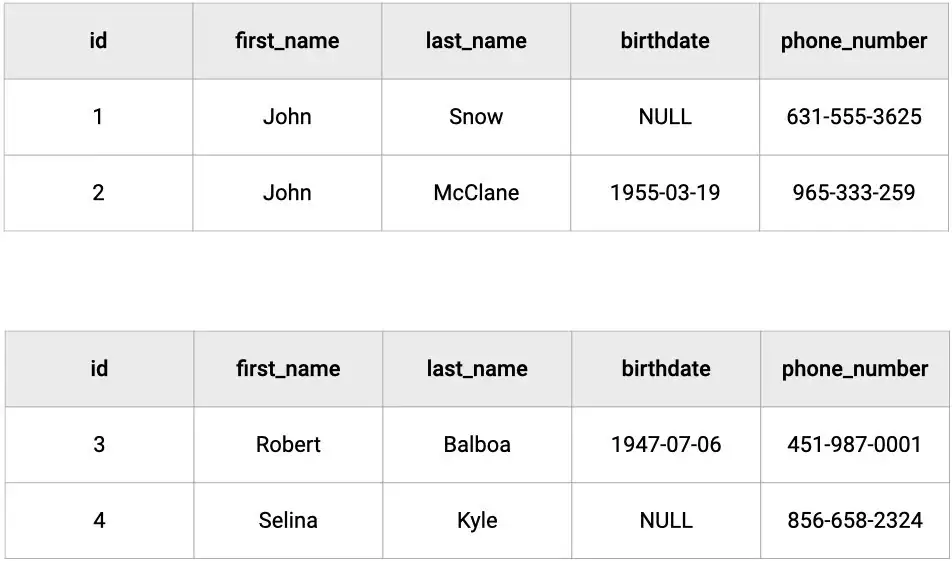
Vertical sharding
In vertical sharding, the attributes of the tables are divided into smaller tables, where the data is broken up by attribute; which means that tables will have both different attributes and records.
Sharding benefits
The benefit of this approach is that it greatly decreases the response delay, as well as providing an increased resiliency to failures.
Executing a simple request on sharded data will be more efficient as the search will only be performed on a subset of records, and since shards are more likely to be located on different machines, the impact on the system of a server becoming unavailable is mitigated.
Sharding challenges
On the flip side, the complexity automatically increases when handling queries that require data-joins.
Moreover, the addition of extra shards can prove challenging without the right database management system, as there might be a need to take the entire database down in order to rebalance the data.
Finally, resiliency might not actually be improved if one or more shards are unavailable because of a lack of data replication.
Scaling for writes is therefore quite tricky and really requires to explore the different capabilities of the various databases (i.e. Relational, NoSQL) available on the market.

